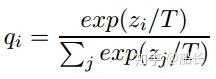知识蒸馏 (Knowledge Distillation)
模型压缩与加速的经典方法
基于 Hinton 2014年 NIPS 论文《Distilling the Knowledge in a Neural Network》
引言
知识蒸馏是模型压缩和加速的经典方法之一
2014年NIPS上由Google的Hinton首次提出
核心思想:将大模型学到的知识转移到小模型上
目标:在保持性能的同时,减小模型大小和计算量
知识蒸馏的基本思路
复杂网络:参数多,计算量大,性能好
小型网络:参数少,计算量小,但难以达到大模型的性能
集成学习:使用多个大模型提升整体性能
问题:如何在保持性能的同时减小模型规模?
提升性能和落地部署不要用相同的模型
常见开发范式:训练大模型 → 部署大模型
作者观点:
用一样的模型是不对的
应该用不同的模型:
训练用复杂大模型:目标为提高性能
部署用小模型:目标为速度和节约资源
类似昆虫的幼体形态(提取能量)和成虫形态(迁徙繁殖)
大模型的Softmax输出概率里面富含知识
通常认为知识体现在模型参数中,难以精简
从更高层次看:知识是
将输入向量映射到输出向量的函数
Softmax输出不仅包含正确类别的概率,还包含错误类别的相对概率
这些相对概率包含大量有用信息:
例:宝马轿车被分类为垃圾车的概率 > 被分类为胡萝卜的概率
我们要学的不是真值标签!要学的其实是泛化能力!
训练目标:提升模型在未见样本上的泛化能力
通常简化为:提升模型在训练集上对真值标签的预测能力
问题:
如果我们已经有了一个泛化能力很强的模型,为什么不让小模型直接学习它的泛化能力呢?
直接学习大模型的泛化能力比学习真值标签更有效
怎么学习泛化能力呢?知识蒸馏!
知识蒸馏:将大模型对样本输出的概率向量作为
软目标(soft targets)
让小模型的输出尽量接近软目标(而非One-hot编码)
训练样本:
可与训练大模型的样本相同
也可使用独立的Transfer集
优势:
"soft targets"比One-hot编码携带更多信息
训练小模型时可用更少的训练集和更大的学习率
当"soft targets"携带信息太少怎么办?用高温T煮出来!
问题:对于简单任务(如MNIST),大模型输出的soft targets接近One-hot编码
重要信息集中在值很小的概率上,但对交叉熵影响小
解决方案:
Caruana方法:使用logits(Softmax的输入)作为学习目标
Hinton方法:
引入温度参数T放大(蒸馏)小概率值携带的信息
Caruana方法是Hinton方法的特例
关于训练集
知识蒸馏训练小模型的训练集:
可以是无标签的数据
也可以是最初训练大模型的数据
实际应用:
有最初训练大模型的带标签训练集效果更好
训练小模型的目标函数可包含两部分:
让小模型预测大模型的Soft target
让小模型预测样本的真值标签
加入真值标签损失有助于小模型学习Soft target
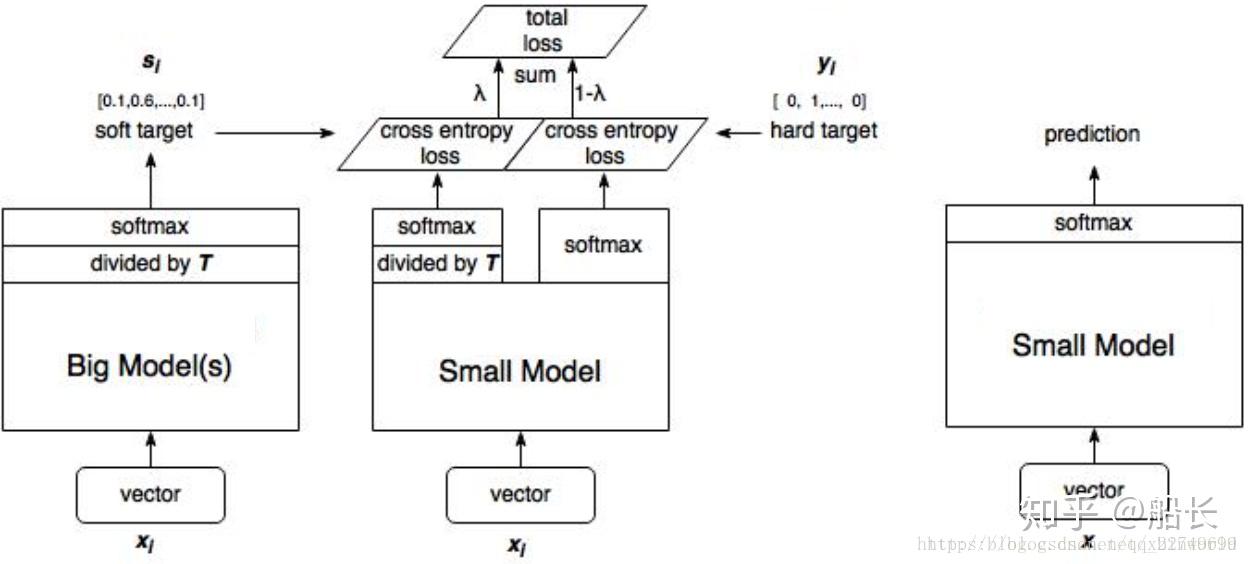
蒸馏过程
左图和中间图:训练过程
右图:预测过程
步骤:
训练一个大模型(性能良好)
用大模型训练小模型
引入温度T,计算Soft target
小模型输出与Soft target的交叉熵作为损失的一部分
预测时不需要温度T
再来说说T的取值
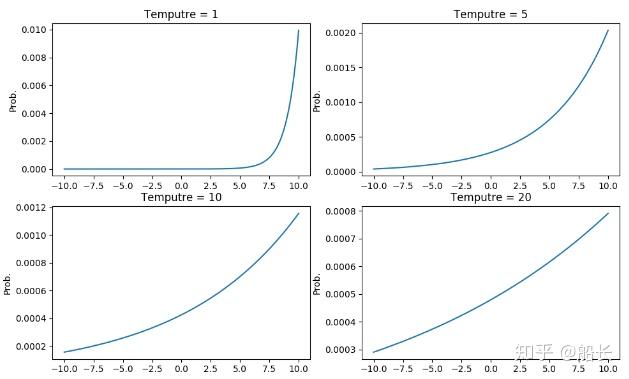
温度T的作用:放大小概率携带的信息
温度T越高:
软目标越平滑
信息不会集中在少数分量上
温度T的取值是经验性问题
当小模型非常小时,适中(偏小)的温度T效果最好
总结
Hinton首次提出知识蒸馏概念并引入温度系数
知识蒸馏可作为模型加速和压缩的方法
核心思想:
训练用大模型,部署用小模型
小模型学习大模型的泛化能力
使用soft targets而非hard targets
引入温度T放大有用信息
实际应用中需考虑温度选择、数据集选择等细节
参考资料
Distilling the Knowledge in a Neural Network
https://arxiv.org/abs/1503.02531
Model Compression
https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf
知识蒸馏、在线蒸馏
https://blog.csdn.net/xbinworld/article/details/83063726
上一页
1 / 13
下一页
保存